如何绘制旅行地图
引言#
在我们分享旅行经历时,地点始终是读者关注的核心。
对于熟悉的城市,简单的地名或定位信息可能已经足够。
但当目的地是国外、冷门或路线复杂的区域时,单靠文字和照片往往难以让人准确理解去了哪里、怎么移动的、景点之间的关系如何。
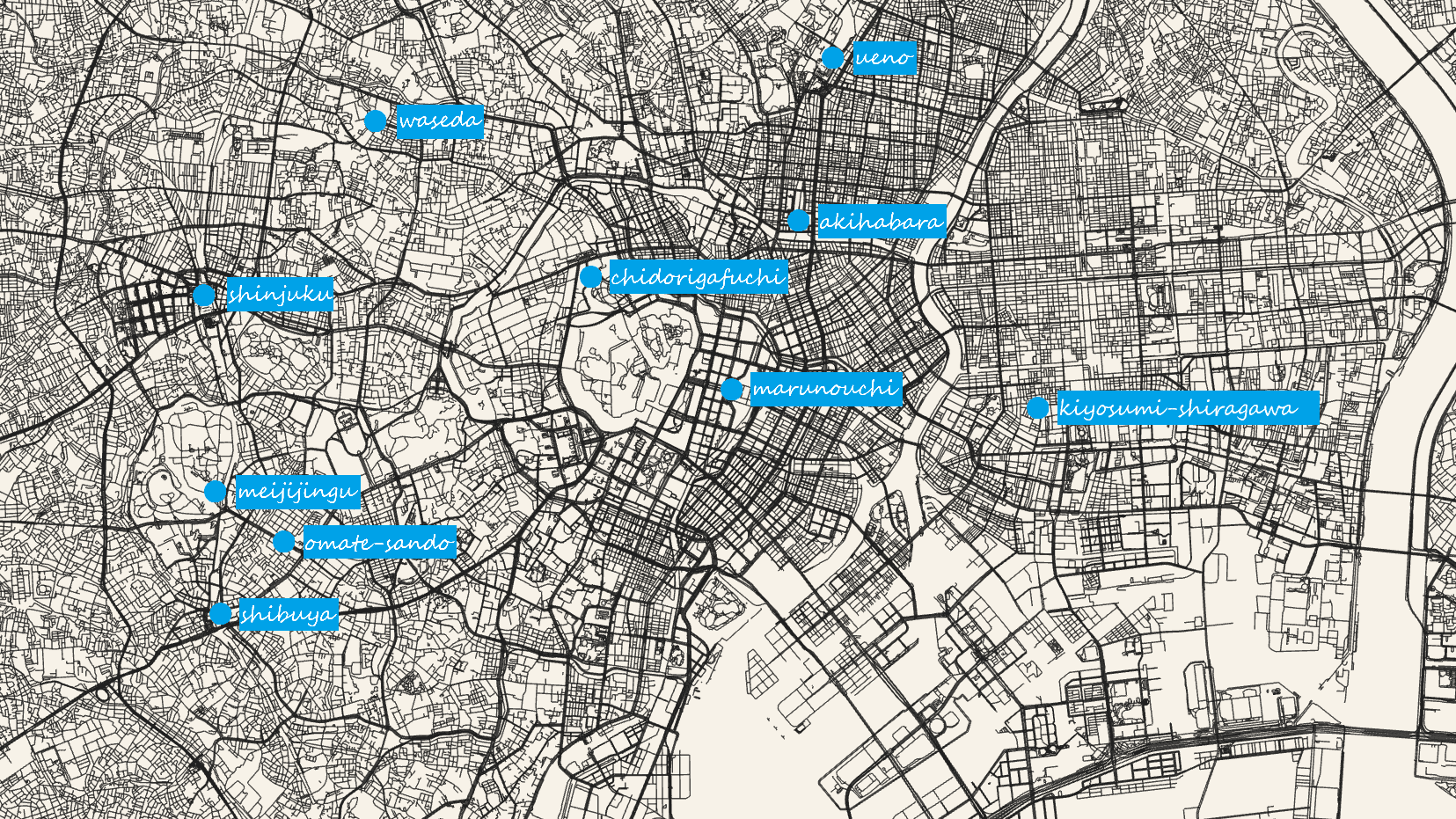
例如新宿和东京是什么关系,为什么在日本可以不换车直达周边某个城市。
这时,一张清晰的旅行地图就能起到关键作用——不仅能提供地理上下文,也能让整篇博文更具条可读性,方便他人计划自己的行程。
本文提供了两种地图的绘制方法:城市路网点位图和铁路路线图
方法一:城市路网点位图#
绘制城市路网基于下面的连接:
https://anvaka.github.io/city-roads
这个项目的作者基于 OpenStreetMap 的数据,实现了查询城市并可视化路网。
OpenStreetMap 的数据保存了多国语言版本,使用中文搜索也没关系,例如我们可以打开网站并搜索鞍山。
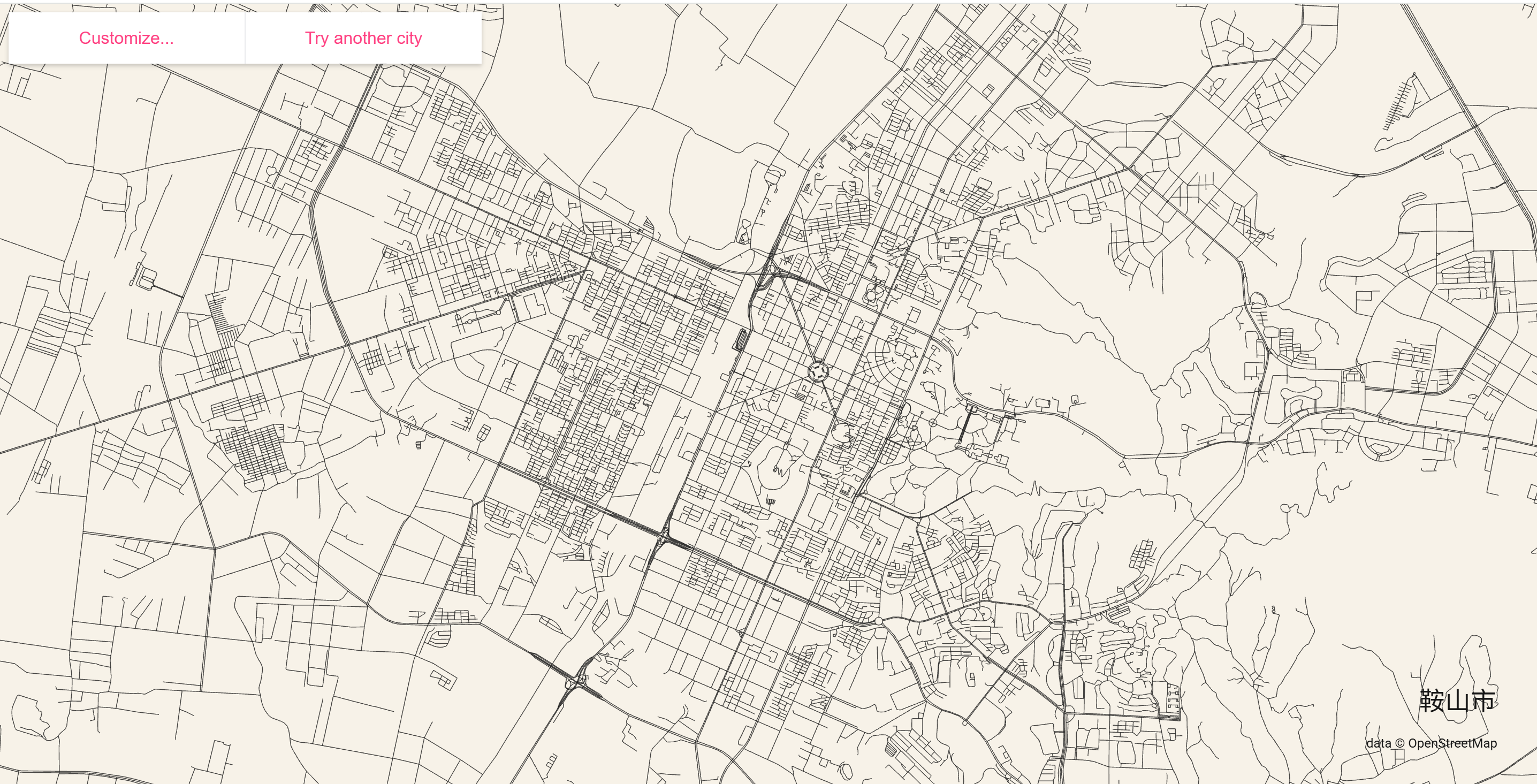
在这个界面可以自由缩放选择自己喜欢的路网密度。
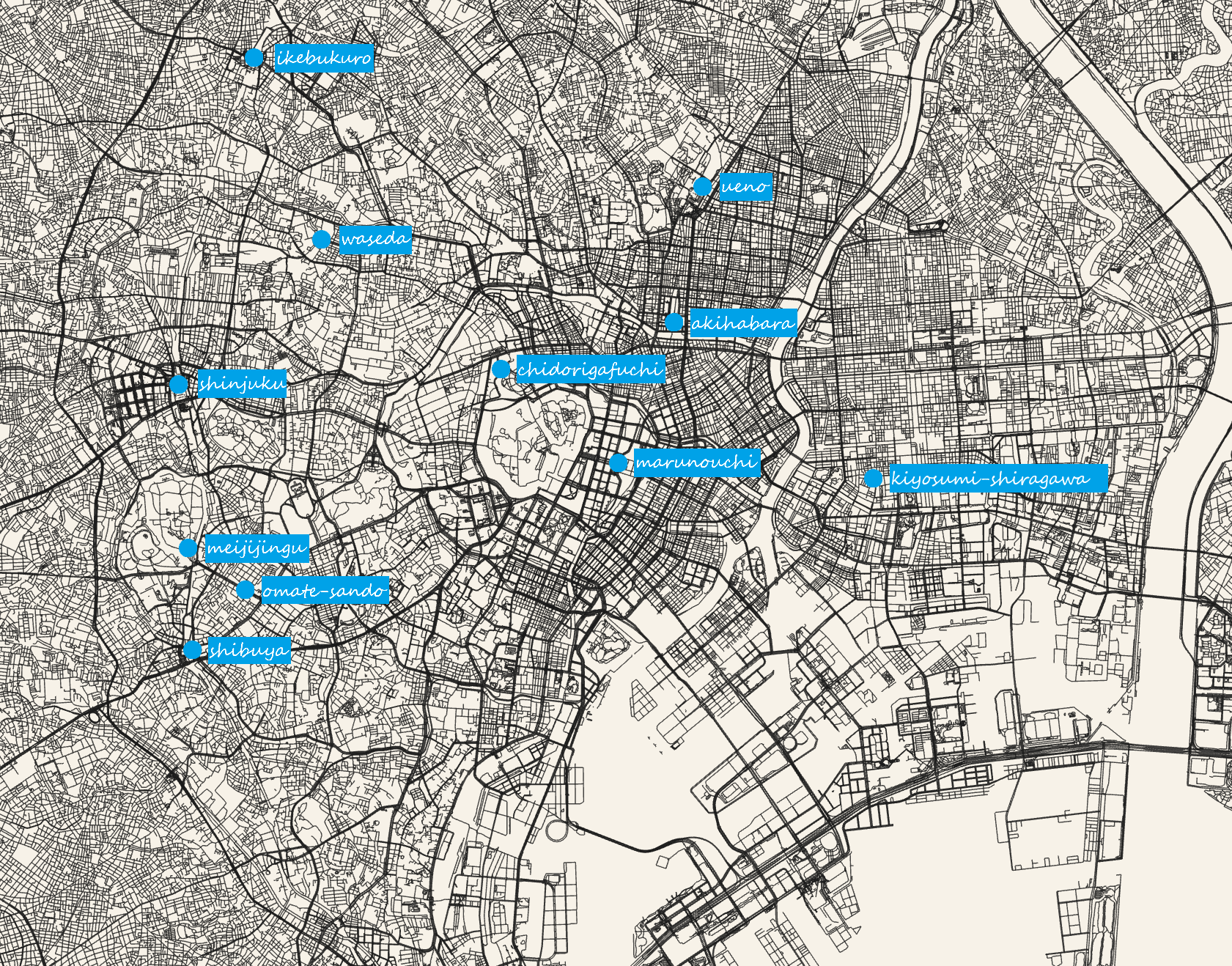
随后我们可以基于简单的黑白路网图添加自己喜欢的表示和标签,方法有很多种,最简单的是使用 windows 自带的画图插入文字,如前面展示的城市点位图(东京)。
也可以选择其他拥有更丰富功能的工具,画出自己喜欢的版本
方法二:铁路图#
铁路图的绘制同样要依赖于 OpenStreetMap 的数据,类似 https://overpass-turbo.eu/ 的网站提供了优秀的查询视图。
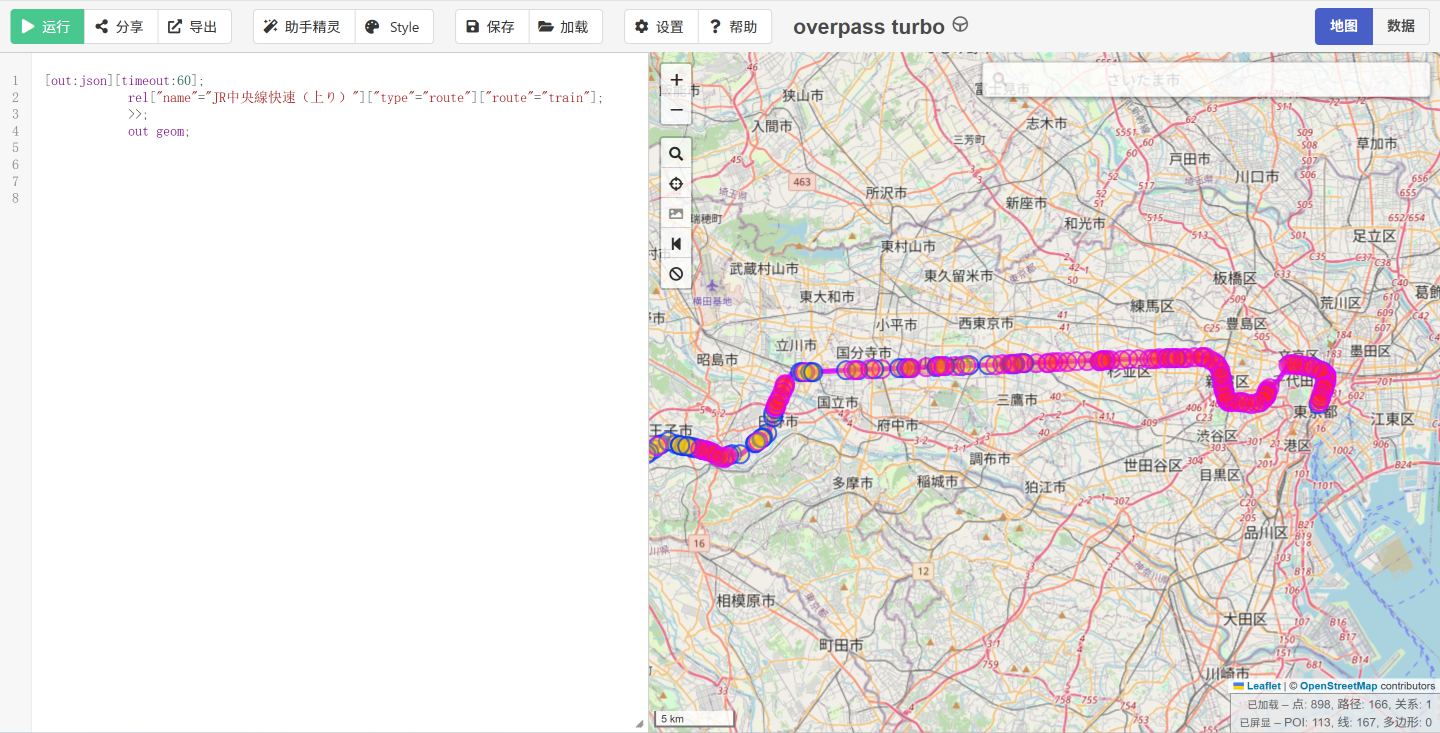
在大模型时代,我们甚至不需要学会这种查询语言,大模型可以帮助我们完成查询语言的编写。
overpass 也支持爬虫访问他们的 api,我们也可以使用简单的爬虫程序得到我们想要的数据。
- 首先导入一些必须的库和目标地址
import requests
import gpxpy.gpx
import time
import os
import copy
OVERPASS_URL = "https://overpass-api.de/api/interpreter"
- 基于车站名查询从本站出发的线路
def fetch_line_names_near_station(station_name="新宿駅", radius=1000):
print(f"开始查询车站周边线路名称: {station_name}")
query = f"""
[out:json];
node["name"="{station_name}"]->.target_station;
(
relation(around.target_station:{radius})
["type"="route"]
["route"~"^(railway|subway|train)$"];
);
out tags;
"""
try:
response = requests.post(OVERPASS_URL, data={"data": query})
response.raise_for_status()
data = response.json()
line_names = set()
for element in data.get("elements", []):
tags = element.get("tags", {})
name = tags.get("name")
if name:
line_names.add(name)
print(f"发现 {len(line_names)} 条线路。")
return list(line_names)
except Exception as e:
print(f"获取线路名称时出错: {e}")
return []
- 基于线路名查询完整信息,并于大小自动分割保存到不同文件中
def create_gpx_from_line_names(line_names, filenameindex, max_size_bytes=4_500_000, ):
ROUTE_TYPES = ["railway", "train", "subway"]
part_index = 1
gpx = gpxpy.gpx.GPX()
# current_size 变量不再需要,因为我们采用更精确的分割方法
def save_gpx(gpx_obj, index):
"""辅助函数,用于保存GPX对象到文件。"""
# 检查对象是否为空,避免保存空文件
if not gpx_obj.tracks and not gpx_obj.waypoints:
print(f"信息: 分卷 {index} 为空,跳过保存。")
return
filename = filenameindex + str(index) + ".gpx"
try:
xml_content = gpx_obj.to_xml()
with open(filename, "w", encoding="utf-8") as f:
f.write(xml_content)
size_kb = len(xml_content.encode('utf-8')) / 1024
print(f"\n成功: 已保存 {filename} (大小: {size_kb:.1f} KB)")
except Exception as e:
print(f"错误: 保存文件时出错: {e}")
for line_name in line_names:
print(f"--- 查询线路: {line_name} ---")
data = None
for route_type in ROUTE_TYPES:
query_template = f"""
[out:json][timeout:180];
rel["name"="{line_name}"]["type"="route"]["route"="{route_type}"];
out body;
>>;
out geom;
"""
try:
response = requests.post(OVERPASS_URL, data={"data": query_template}, timeout=180)
response.raise_for_status()
data = response.json()
if data.get("elements"):
break # 找到数据后即退出循环
except requests.exceptions.RequestException as e:
print(f"警告: 查询类型 '{route_type}' 失败: {e}")
data = None
time.sleep(1)
if not data or not data.get("elements"):
print(f"信息: 未找到线路 '{line_name}' 的数据,跳过。")
time.sleep(1)
continue
# 将返回的元素分类,便于查找
nodes = {el['id']: el for el in data['elements'] if el['type'] == 'node'}
ways = {el['id']: el for el in data['elements'] if el['type'] == 'way'}
relations = [el for el in data['elements'] if el['type'] == 'relation']
if not relations:
print(f"信息: 未在返回数据中找到 'relation',无法处理 '{line_name}'。")
continue
# 只处理找到的第一个关系
relation = relations[0]
gpx_track = gpxpy.gpx.GPXTrack(name=line_name)
new_waypoints = [] # 用于存放当前线路的站点
# 遍历关系成员,提取轨迹和站点
for member in relation.get('members', []):
if member.get('type') == 'way':
way = ways.get(member.get('ref'))
if way and 'geometry' in way:
# 每个way创建一个segment,保证轨迹段落的独立性
gpx_segment = gpxpy.gpx.GPXTrackSegment()
for point in way['geometry']:
gpx_segment.points.append(
gpxpy.gpx.GPXTrackPoint(latitude=point["lat"], longitude=point["lon"])
)
if gpx_segment.points:
gpx_track.segments.append(gpx_segment)
elif member.get('type') == 'node' and member.get('role') in ('stop', 'station'):
node = nodes.get(member.get('ref'))
if node:
# 创建航点(站点),只包含基本信息
waypoint = gpxpy.gpx.GPXWaypoint(
latitude=node.get('lat'),
longitude=node.get('lon'),
name=node.get('tags', {}).get('name')
)
new_waypoints.append(waypoint)
# 检查是否为当前线路提取到了任何数据
if not gpx_track.segments and not new_waypoints:
print(f"信息: 未能为 '{line_name}' 提取任何有效的轨迹或站点。")
continue
# 修复后的文件分割逻辑
# 创建一个临时的GPX对象来估算添加新数据后的大小
temp_gpx = copy.deepcopy(gpx)
if gpx_track.segments: # 仅当轨迹有内容时才添加
temp_gpx.tracks.append(gpx_track)
temp_gpx.waypoints.extend(new_waypoints)
temp_xml_size = len(temp_gpx.to_xml().encode('utf-8'))
# 如果当前GPX对象非空,并且加入新数据后会超限
if (gpx.tracks or gpx.waypoints) and temp_xml_size > max_size_bytes:
print(f"信息: 文件大小超出限制,创建新分卷。")
# 先保存当前已有的内容
save_gpx(gpx, part_index)
part_index += 1
# 然后用新数据创建一个全新的GPX对象
gpx = gpxpy.gpx.GPX()
if gpx_track.segments:
gpx.tracks.append(gpx_track)
gpx.waypoints.extend(new_waypoints)
else:
# 如果不超限,直接添加
if gpx_track.segments:
gpx.tracks.append(gpx_track)
gpx.waypoints.extend(new_waypoints)
print(f"成功: 添加轨迹 '{line_name}' ({len(gpx_track.segments)}个路段, {len(new_waypoints)}个站点)")
time.sleep(2)
# 循环结束后,保存最后一部分
if gpx.tracks or gpx.waypoints:
save_gpx(gpx, part_index)
- 调用相关函数完成数据收集
line_names = fetch_line_names_near_station("東京駅", radius=1000)
create_gpx_from_line_names(line_names, "tokyo_route_")
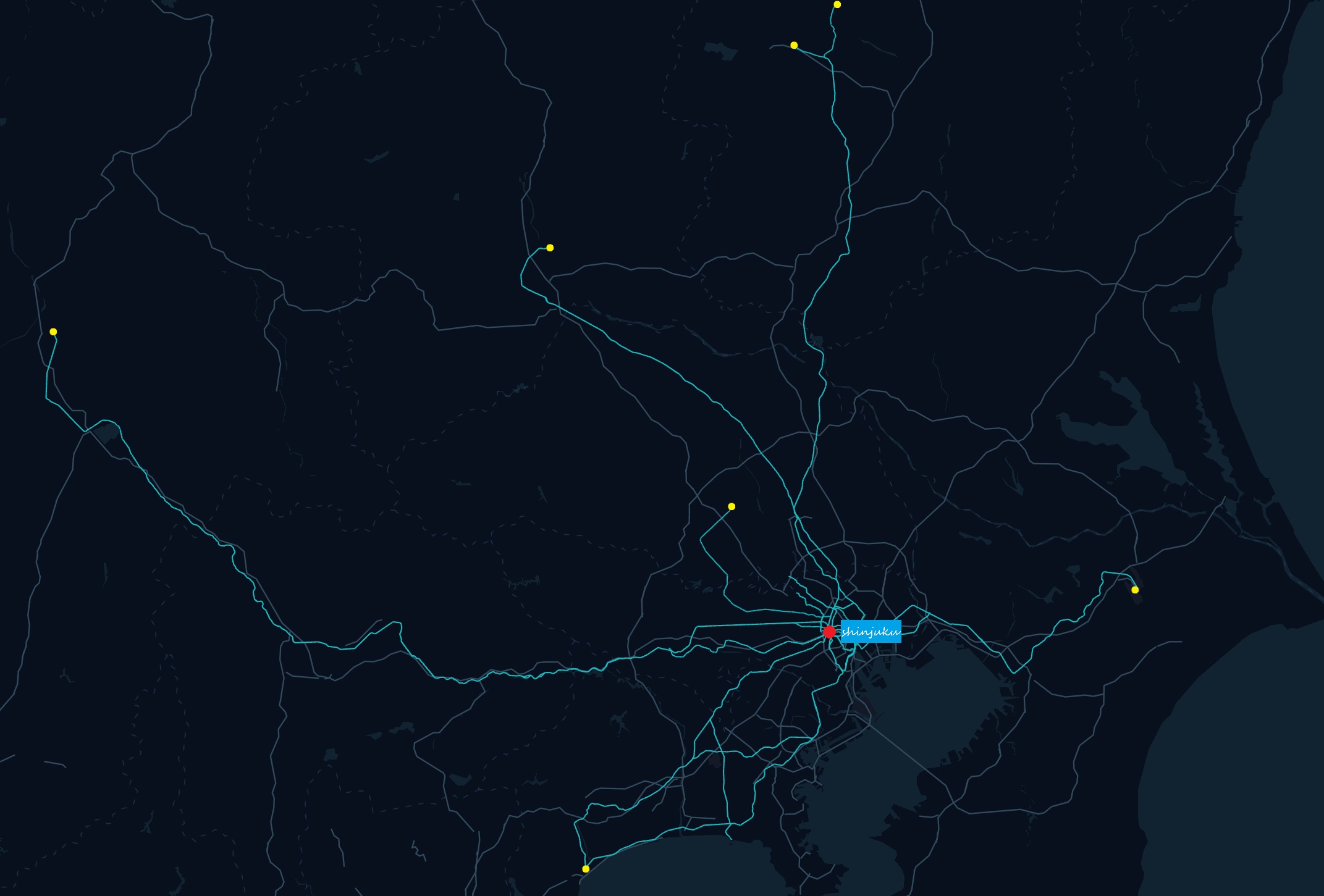
在使用爬虫或手动完成数据收集后,我们可以打开 Google Map 的自制地图服务:
https://www.google.com/intl/zh-CN/maps/about/mymaps/
在这里导入我们收集到的 GPX 类型数据,如:
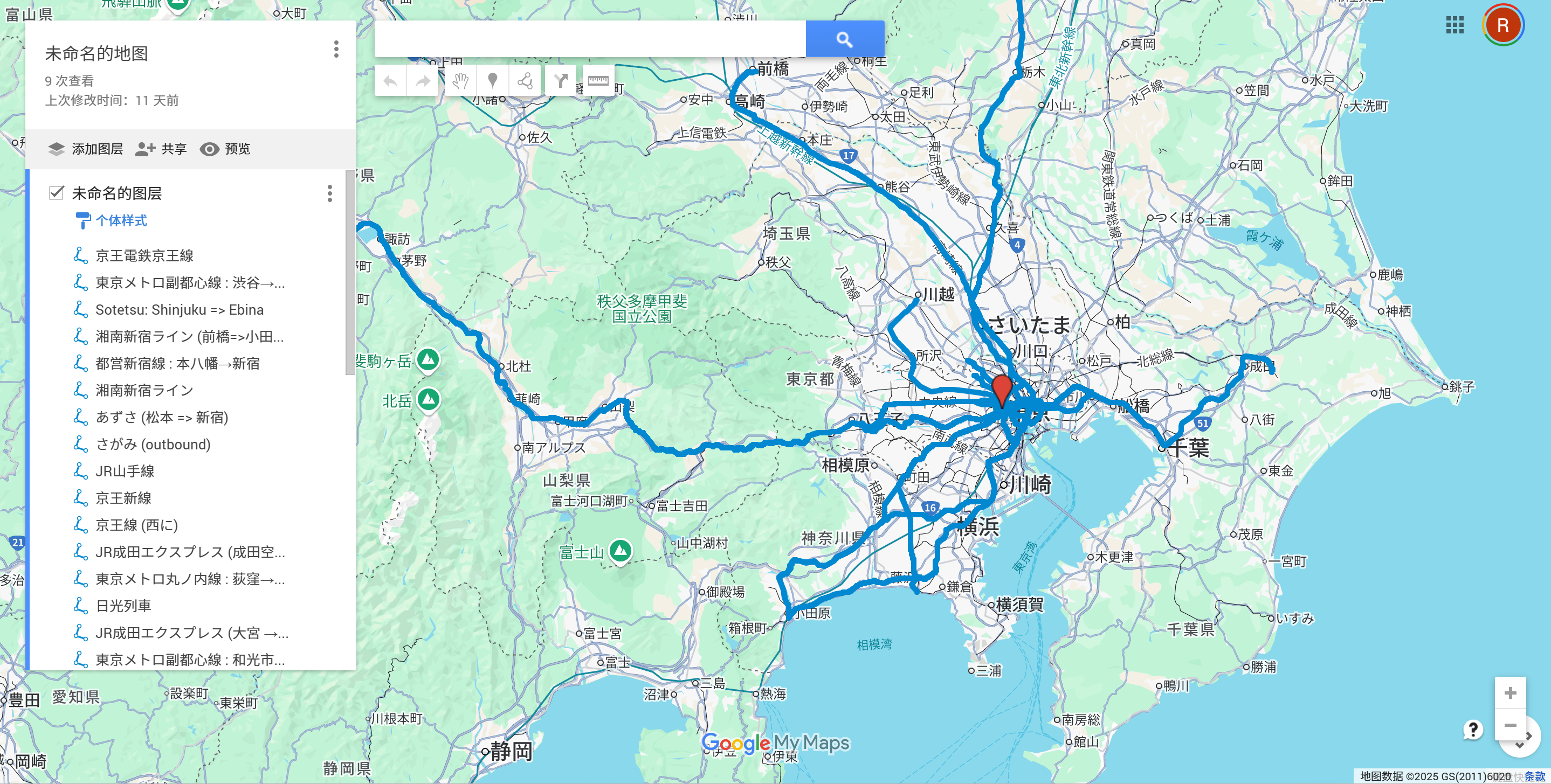
可以手动添加图层或删除不必要的节点,来完成我们想要的版本。
vscode 也有 Geo View 相关插件,也可以用于预览数据。